
We live in a REST era where JSON or XML is our text-based format default choice of text-based formats and widespread use by major corporations. However, one of the most ancient and common standards for message representation is using text files (Flat Files) like CSV (Comma Separated Values) or TXT files, many of which are custom-made for their systems. Do not be fooled into thinking these messages are outdated and rarely used. A good example is EDI messages, which are used extensively by large companies, so it is often necessary to transform text files into XML and vice versa.
Still today, many existing integrations and new integrations are made based on Flat Files.
📝 One-Minute Brief
Flat files are still widely used in enterprise integrations. This article explains how Logic Apps support flat files, what flat‑file schemas are, and how you can process headers, bodies, and trailers when integrating CSV or text‑based messages.
What are Flat Files?
The standard definition states that a flat file is a collection of data stored in a two-dimensional database in which similar yet discrete strings of information are stored as records in a table. The table’s columns represent one database dimension, while each row is a separate record. Or in other words, it is a type of data storage file in which data is stored as plain text, often in a table-like structure with rows and columns. Each row represents a single record, while columns represent fields or attributes of the data. The information stored in a flat file is generally alphanumeric with little or no additional formatting. The structure of a flat file is based on a uniform format as defined by the type and character lengths described by the columns.
Flat files serve various purposes in software development, primarily for data storage, exchange, and processing tasks. They are widely used due to their simple structure, human readability, and ease of manipulation across different platforms and applications. For instance, flat files are commonly employed in data import and export operations, where applications or systems with diverse data storage mechanisms must communicate or transfer data.
A flat-file instance message is a text file that can contain three logical parts:
- A header.
- A body.
- And a trailer.
In that order. Of course, both the header and the trailer are optional. The following example shows a flat-file instance message consisting of all three parts, with the body in bold type:
Sandro Pereira
Porto, Portugal
PO,1,BOOK,4415
TRANS-1
If you come from a Microsoft BizTalk Server background or if you are migrating a BizTalk Server project using these types of flat files, you may know that the Flat file disassembler’s parsing allows you to specify:
- The Header Schema in the Header schema design-time property of the flat file disassembler or the XMLNORM.HeaderSpecName message context property.
- The Body Schema in the Document schema design-time property of the flat file disassembler or the XMLNORM.DocumentSpecName message context property.
- And the Trailer Schema in the Trailer schema design-time property of the flat file disassembler or the XMLNORM.TrailerSpecName message context property.
However, Logic Apps only supports Body Schemas. You cannot have different schemas for Headers, Bodies, and Trailers. You can still process these types of flat-file messages, but in a different approach with a single Schema dividing what a header, body, and trailer are in different records (structures).
Flat-File Schema Types
Within a particular part of a flat-file instance message, different data items are grouped into records, which themselves can contain sub-records and, ultimately, individual data items known as fields. These records and fields are distinguished from each other using one of two different basic methodologies.
- The first methodology, known as positional, defines each data item as a pre-established length, with pad characters being used to bring a shorter item of data up to its expected length.
- The second methodology, known as delimited, uses one or more special characters to separate items of data from each other. This methodology avoids the need for otherwise superfluous pad characters. Still, it introduces some special considerations when the data itself contains the character or sequence of characters being used as a delimiter.

Positional Flat Files
Positional records within a flat-file instance message contain individual fields (data items) that are each of a predefined length. The fields are parsed according to these lengths. For example, consider the following positional record from a flat-file instance message containing an id, country code, client name, and Country name:
01 PT Sandro Pereira Portugal
A reasonable definition for this record in a flat-file schema can be described as follows:
- A positional record named Client contains the following fields:
- An attribute named id that is left-aligned, three characters in length, with a zero character offset.
- An element named countryCode that is left-aligned, three characters in length, with a zero character offset.
- An element named name that is left-aligned, 37 characters in length, with a zero character offset.
- An element named country that is left-aligned, and the length is until the end of the line.
Given these record and field definitions, the Flat file disassembler will produce the following XML equivalent of this record:
<Client id=01 ">
<countrCode>PT </countrCode>
<name>Sandro Pereira </name>
<country>Portugal</country>
</Client>
There are several considerations related to positional records that will affect how the record is parsed when received and constructed when sent, including:
- The character used to fill the unused portion of each field is known as the pad character.
- An optional tag within the record can be used to distinguish the record from other similar records. Tags usually occur at the beginning of the record, but are allowable anywhere within it. Positional records can be defined to have a tag or not have a tag, but once defined, the tag must be present or not, based on the definition.
- How data is justified within a fixed-length field relative to the accompanying pad characters.
- Positional records nested within other positional or delimited records.
- Positional records with field lengths specified as a specific number of bytes rather than a specific number of characters.
Notes:
- Suppose your flat file contains both delimited and positional records. In that case, you must set the Structure property of the root node to Delimited and the Structure property of subordinate record nodes to either Delimited or Positional as appropriate.
- Fields in positional records have a limit of 50000000 characters.
Delimited Flat Files
Delimited records within a flat-file instance message contain nested records and/or individual fields (items of data) that are separated by a predefined character or set of characters. The fields are parsed according to these separating delimiters. For example, consider the following delimited records from a flat-file instance message, which contain three client lines to add to our internal system hypothetically:
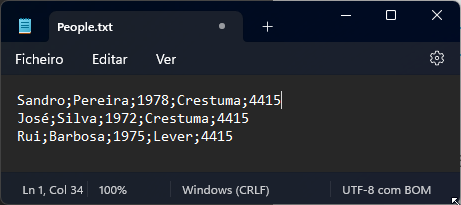
Sandro;Pereira;1978;Crestuma;4415
José;Silva;1972;Crestuma;4415
Rui;Barbosa;1975;Lever;4415
A reasonable definition for this record in a flat-file schema can be described as follows:
- A delimited repeating record named Client with child delimiter {CR}{LF}
- And delimited elements with a child delimiter ;
- firstName
- lastName
- birthYear
- city
- zipCode
Given these record and field definitions, the Flat file disassembler produces the following XML equivalent of these records.
<Client>
<firstName>Sandro</firstName>
<lastName>Pereira</lastName>
<birthYear>1978</birthYear>
<city>Crestuma</city>
<zipCode>4415</zipCode>
</Client>
<Client>
...
</Client>
...
There are several considerations related to delimited records that will affect how the record is parsed when received and constructed when sent, including:
- The character or characters are used to override the interpretation of delimiters so that they are treated as part of the data.
- An optional tag at the beginning of the record can be used to distinguish the record from other similar records.
- How data is justified within fields with minimum lengths relative to the accompanying pad characters.
- Positional records nested within other delimited records.
- How data is justified within a fixed-length field relative to its accompanying pad characters.
Preservation and suppression of delimiters when flat-file messages are received and sent.
Notes:
- Suppose your flat file contains both delimited and positional records. In that case, you must set the Structure property of the root node to Delimited and the Structure property of subordinate record nodes to either Delimited or Positional as appropriate.
- Delimited fields in flat files have a limit of 50000000 characters.
How do Logic Apps process the text files (Flat Files)?
When building a logic app workflow in Azure Logic Apps, you can encode and decode flat files using the Flat File built-in connector actions and a flat file schema for encoding and decoding. You can use Flat File actions in multi-tenant Consumption logic app workflows and single-tenant Standard logic app workflows.
- Inside Logic Apps Consumption, an Integration Account is required to store the flat-file schemas and use the Flat File built-in connector.
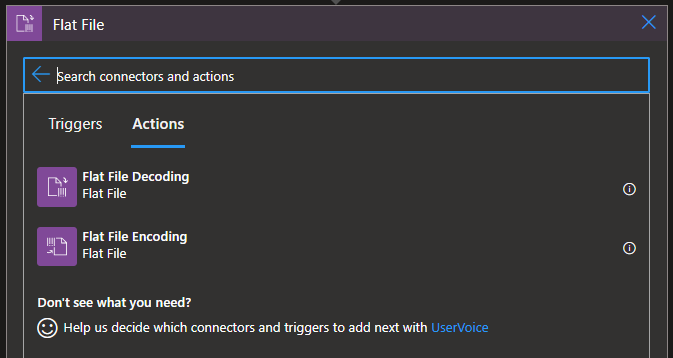
- Inside Logic Apps Standard, there is no need for having an Integration Account since Schemas are supported built-in. However, if you desire, you can still use the Integration Account.
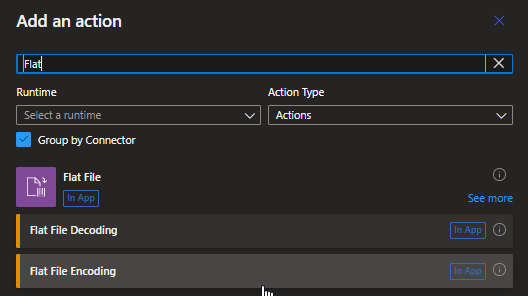
While no Flat File triggers are available, you can use any trigger or action to feed the flat-file content into your workflow. For example, you can use a built-in connector trigger, a managed or Azure-hosted connector trigger available for Azure Logic Apps, or even another app, like the Request built-in trigger or File System trigger.
Flat File Encoding action
The Flat File Encoding action allows you to convert an XML message into a flat file. Note that this action does not validate the incoming XML message. For that, you need to use the XML Validation action.
In Logic Apps Consumption, this action allows the following inputs:
- The Content property, where you specify the XML message you want to encode to a flat file.
- The Schema Name property is where you choose the flat-file body Schema or the Document schema.
- If the schema list is empty, either your logic app resource isn’t linked to your integration account or doesn’t contain any schema files.
- And then we have the following optional properties:
- Mode of empty node generation, where we specify the mode to use for empty node generation with flat file encoding. Possible values are ForcedDisabled, HonorSchemaNodeProperty, or ForcedEnabled.
- XML Normalization allows you to enable or disable XML normalization in flat file encoding. Possible values are Yes or No.
In Logic Apps Standard, this action allows the following inputs:
- The Content property, where you specify the XML message you want to encode into a flat file.
- In the Source property, we select either LogicApp or IntegrationAccount as your schema source.
- The Name property is where you choose the flat-file body Schema or the Document schema.
- If the schema list is empty, either your logic app resource isn’t linked to your integration account, your integration account doesn’t contain any schema files, or your logic app resource doesn’t contain any schema files.
- And then we have the following optional properties:
- Mode of empty node generation, where we specify the mode to use for empty node generation with flat file encoding. Possible values are ForcedDisabled, HonorSchemaNodeProperty, or ForcedEnabled.
- XML Normalization allows you to enable or disable XML normalization in flat file encoding. Possible values are Yes or No.
Flat File Decoding action
The Flat File Decoding action allows you to convert a flat-file message into an XML message. Note that this action does not validate the outcome XML message. For that, you need to use the XML Validation action.
In Logic Apps Consumption, this action allows the following inputs:
- The Content property, where you specify the flat-file message you want to decode to XML.
- The Schema Name property is where you choose the flat-file body Schema or the Document schema.
- If the schema list is empty, either your logic app resource isn’t linked to your integration account or doesn’t contain any schema files.
In Logic Apps Standard, this action allows the following inputs:
- The Content property, where you specify the flat-file message you want to decode to XML.
- In the Source property, we select either LogicApp or IntegrationAccount as your schema source.
- The Name property is where you choose the flat-file body Schema or the Document schema.
- If the schema list is empty, either your logic app resource isn’t linked to your integration account, your integration account doesn’t contain any schema files, or your logic app resource doesn’t contain any schema files.
Unlike BizTalk Server, where these Syntax Transformations or Data translation typically happen inside receive or Send Pipelines. Inside Logic Apps, they happen inside our business process, aka Logic App, using the Flat File connector.
Hope you find this useful! So, if you liked the content or found it useful and want to help me write more content, you can buy (or help buy) my son a Star Wars Lego!

Hi Sandro, if we are using integration account then this is the best way to use flat file schema. We can add those schema into integration account and we can use flat file decoder or encoder schema here. For delimited flat file there is a possibility To implement without using integration account. We can write split expression. if the project don’t use intervention account it’s time taking process.
Thanks for your information it will be very helpful.