You may already know my BizTalk Pipeline Components Extensions Utility Pack project available on GitHub for those who follow me. The project is a set of custom pipeline components (libraries) that can be used in received and sent pipelines, extending BizTalk’s out-of-the-box pipeline capabilities.

This month, my team and I updated this project with another new component: the ODBC File Decoder Pipeline Component.
📝 One-Minute Brief
A new pipeline component added to the BizTalk Pipeline Components Extensions Utility Pack that enables BizTalk Server to decode and process Excel and DBF files using ODBC. It converts these files into XML through ADO.NET, filling a long-standing gap in BizTalk’s native capabilities—especially for Excel‑based integrations.
ODBC File Decoder Pipeline Component
ODBC File Decoder Pipeline Component is, as the name suggests, a decode component that you can use in a receive pipeline to process DBF or Excel files. Still, it can be possible to process other ODBC types (maybe requiring minor adjustments). The component uses basic ADO.NET to parse the incoming DBF or Excel files into an XML document.
If consuming DBF files is not a typical scenario, we can’t say the same for Excel files. Yet, we often find these requirements, and there isn’t any out-of-the-box way to process these files.
Honestly, I don’t know the original creator of this custom component. I came across this old project that I found interesting while organizing my hard drives. However, when I tested it in BizTalk Server 2020, it wasn’t working correctly, so my team and I improved and organized the structure of the code of this component to work as expected.
How does this component work?
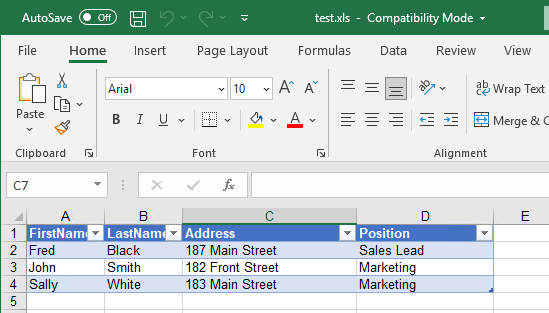
If we take an example and an Excel File (.xls) that has a table with:
- FirstName
- LastName
- Address
- Position
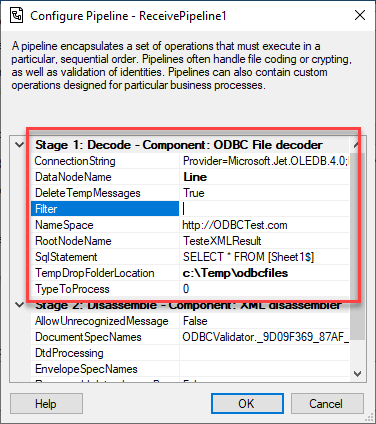
We can use the ODBC File Decoder Pipeline Component to process these documents. First, we need to create a custom pipeline component and add this component to the decode stage. Once we publish this pipeline, we can configure it as follows to be able to process these types of Excel documents:
- ConnectionString: ODBC Connection String.
- For Excel documents: Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=Excel 8.0;
- For DBF: Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=dBASE IV;
- DataNodeName: Rows node name for the generated XML message.
- For example: Line.
- Filter: Filter for Select Statement.
- Leave it empty.
- NameSpace: Namespace for the generated XML message.
- For example: http://ODBCTest.com.
- RootNodeName: Root node name for the generated XML message.
- For example: TesteXMLResult.
- SqlStatement: Select Statement to Read ODBC Files.
- For example: SELECT * FROM [Sheet1$]
- TempDropFolderLocation: Support temp folder for processing the ODBC Files.
- For example: c:\Temp\odbcfiles
- TypeToProcess: Type of file being processed.
- 0 to process Excel
- 1 to process DBF
The outcome will be an Excel similar to this:
<?xml version="1.0" encoding="utf-8"?><ns0:TesteXMLResult xmlns:ns0="http://ODBCTest.com">
<Line>
<FirstName>Fred</FirstName>
<LastName>Black</LastName>
<Address>187 Main Street</Address>
<Position>Sales Lead</Position>
</Line>
<Line>
<FirstName>John</FirstName>
<LastName>Smith</LastName>
<Address>182 Front Street</Address>
<Position>Marketing</Position>
</Line>
<Line>
<FirstName>Sally</FirstName>
<LastName>White</LastName>
<Address>183 Main Street</Address>
<Position>Marketing</Position>
</Line>
</ns0:TesteXMLResult>
Does it work with Xlsx files?
Honestly, I didn’t try it yet. I didn’t have that requirement, and I only remember this scenario now that I’m writing this post, but it should be able to process it. The only thing I know is that we need to use a different connection string, something similar to this:
- Provider=Microsoft.ACE.OLEDB.12.0;Data Source=c:\myFolder\myExcel2007file.xlsx;Extended Properties=”Excel 12.0 Xml;HDR=YES”;
- or Provider=Microsoft.ACE.OLEDB.12.0;Data Source=c:\myFolder\myExcel2007file.xlsx;Extended Properties=”Excel 12.0 Xml;HDR=YES;IMEX=1″;
Download
THIS COMPONENT IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND.
You can download the ODBC File Decoder Pipeline Component from GitHub here:
Hope you find this helpful! If you liked the content or found it useful and would like to support me in writing more, consider buying (or helping to buy) a Star Wars Lego set for my son.