
The order in which we perform the links between the elements from source to destination has a huge impact on the final result. This statement is true and false at the same time!
In fact, the order with which we associate links (Drag & Drop) from the source to different destination elements is irrelevant, since the compiler, as previously explained, will process them in the correct order… Except if we have to associate several links to the same destination element or functoid. In these two last cases, the order in which the link association takes place is extremely important and can lead to unexpected results.
📝 One-Minute Brief
In this third part of the “How Maps Work” series, Sandro tackles the critical concept of link sequencing. While the order of dragging links generally doesn’t matter for separate elements, it is vital when multiple links connect to the same functoid or destination element. Sandro demonstrates how the BizTalk engine processes links based on target schema traversal and explains a key exception: when parent node links are executed after child elements (like with custom counter scripts), leading to potential logical errors.
Impact of the order of links in functoids
The functoids require certain input parameters that can vary according to the functoid that we are using, in this case, the order with which we associate the link is extremely important, a practical example is the Value Mapping Functoid.
This functoid returns the value of the second parameter if the value of the first parameter is “true”. If the value of the first parameter is not “true”, the corresponding element or attribute in the output instance message is not created. Therefore, it is necessary to respect the order in which we associate the links:
- The first parameter must be a value “true” or “false”, generally from the output of some other Logical functoid or from a variable Boolean field in the input instance message.
- The second is the value that is output if parameter 1 is “true”. This value can be from a link from a node in the source schema that represents simple content, the output from another functoid, or a constant input parameter.
If we change the order in which the links are associated to the functoid, it will lead to mapping errors or unexpected results, according to the functoid used.
The link reorganization in functoids is very easy to accomplish; you just open the functoid detail (double click) and use the sort buttons.
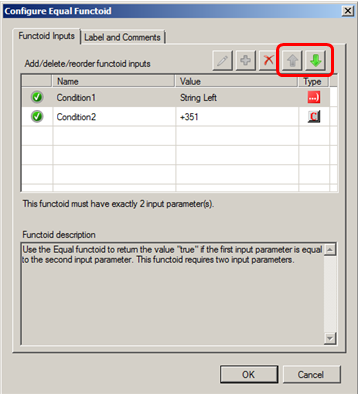
Impact of the order of links in elements of the destination schema
If we change the order in which we associate the links on the same element in the destination schema, we can also have an impact on the desired final result.
Unfortunately, when we associate different links in the same element, there is no way or place in the graphical editor where you can check the order of the association, for example, similarly to what happens with the functoids. The only way to verify the order in these cases is to inspect the XSLT-generated code or test the map.
A good example of this scenario is when we associated two different Scripting functoid, both with custom inline XSLT scripts, to the same destination element or record; once again, changing the order of the link association may have unexpected results.
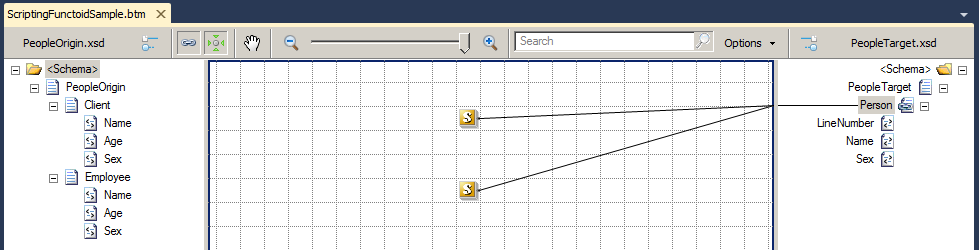
In this example, the first Scripting functoid contains the following XSLT code:
<xsl:for-each select="Client">
<Person>
<Name>
<xsl:value-of select="Name/text()" />
</Name>
<Sex>
<xsl:value-of select="Sex/text()" />
</Sex>
</Person>
</xsl:for-each>
This code performs the mapping of all existing elements in the record Client from the source schema to the elements on the record Person in the destination schema.
The second Scripting functoid contain an identical XSLT code:
<xsl:for-each select="Employee">
<Person>
<Name>
<xsl:value-of select="Name/text()" />
</Name>
<Sex>
<xsl:value-of select="Sex/text()" />
</Sex>
</Person>
</xsl:for-each>
But this time it will map all existing elements in the record Employee from the source schema to the elements on the record “Person” in the destination schema.
The expected result is to appear in the final document all clients in the record Person, and then all employees. If we change the order in which we associate the links in the record Person, we will see that the result will also be changed.
We can validate the result of this scenario in the following links:
- Original Message:
- Expected result:
- The result if we change the order of the association:
The rule of Link Sequence
In brief, the mapping engine processes the rules by going through the destination schema from the beginning to the end, processing the links in the order that it finds, and in the case of multiple links in a particular element or functoid, they are processed in the order in which they were associated.
This means that the links associated with the parent nodes (records) are processed before the links associated with the children (elements inside the record).
A good example of this scenario is the use of conditions in the parent node (a record) when we want to influence the outcome according to a particular condition. So…let’s find all the names of female clients. To do this, we will create a map with the following settings:
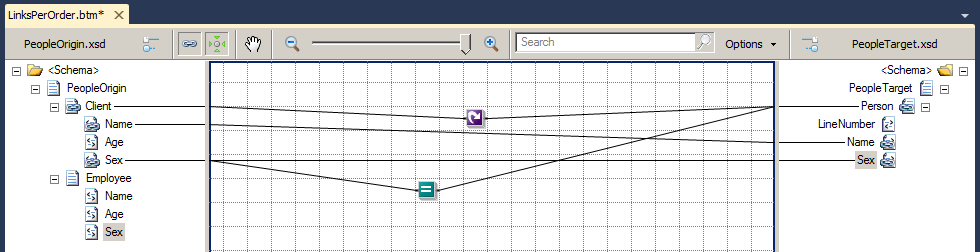
- Open the Toolbox window and drag the Looping Functoid onto the grid.
- Drag a link from the record Client from the source schema to the Looping Functoid.
- Drag a link from the Looping Functoid to the record Person in the destination schema.
- Drag the Equal Functoid from the Toolbox window onto the grid.
- Drag a link from the element Sex from the source schema to the Equal Functoid.
- Drag a link from the Equal Functoid to the record Person in the destination schema.
- Configured the Equal Functoid by double-clicking on the functoid, and edited the second condition with the value “F” to build a condition equivalent to Sex = “F”.
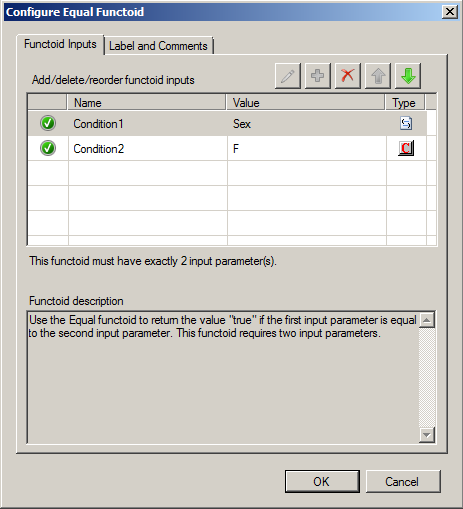
The Equal Functoid will return the value True if the first input, in this case, the element Sex, is equal to the second input parameter, ie, “F”. Otherwise, it will return the value False. What will lead to: the record Client is only mapped if the condition returns the value True.
If you look at the code generated:
…
<ns0:PeopleTarget>
<xsl:for-each select="Client">
<xsl:variable name="var:v1" select="userCSharp:LogicalEq(string(Sex/text()) , "F")" />
<xsl:if test="$var:v1">
<Person>
<Name>
<xsl:value-of select="Name/text()" />
</Name>
<Sex>
<xsl:value-of select="Sex/text()" />
</Sex>
</Person>
</xsl:if>
</xsl:for-each>
</ns0:PeopleTarget>
We can check that the first action of the map, after the cycle that travels the various elements of the record, is: get the value generated in the Equal Functoid, which is represented in the variable “v1”;
And the second action is to validate the condition (IF) with the value of the first operation (v1), ie, it will test whether the value “v1” is “True” or “False”. If the condition is true, the code within the condition is executed; otherwise, it will move to the next element without doing anything. Therefore, we obtain the desired result:
<ns0:PeopleTarget xmlns:ns0="http://HowMapsWorks.PeopleTarget">
<Person>
<Name>Elsa Ligia</Name>
<Sex>F</Sex>
</Person>
</ns0:PeopleTarget>
The exception to the rule of Link Sequence: Process links out of order
However, there is one important exception to this rule of Link Sequence, especially when using custom scripts in recursive records or elements.
Once again, a good example of this scenario is the use of custom scripts to increment counters. We can illustrate this scenario by adding two Scripting Functoids to the map:
- The first contains the initialization and the function to increment the counter.
int myCounter = 0;
public void IncrementCounter()
{
myCounter += 1;
}
- The second is getting the value of the counter.
public int ReturnCounter()
{
return myCounter;
}
Note: This example will be associated with a loop, or with a recursive element.
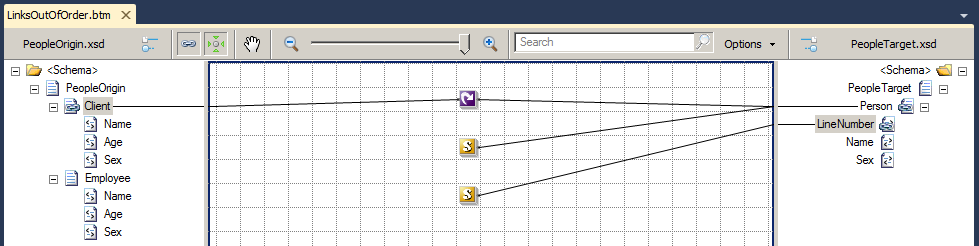
We would expect that in the first cycle, the result of the second script was the value “1”, in the second cycle, we obtained the value “2”, and so on. However, if we test the map, we will see that the reality is different:
<ns0:PeopleTarget xmlns:ns0="http://HowMapsWorks.PeopleTarget">
<Person><LineNumber>0</LineNumber></Person>
<Person><LineNumber>1</LineNumber></Person>
<Person><LineNumber>2</LineNumber></Person>
</ns0:PeopleTarget>
As we can see in the result above, the sequence in which the links are executed is:
- Create the record PeopleTarget.
- Creating child elements and carrying out the link rules associated with them:
- Execute the function ReturnCounter that will return the value “0” in the first iteration.
- Execute the links associated with the parent node:
- Execution of the function IncrementCounter.
As we can validate by checking the code produced by the map:
…
<ns0:PeopleTarget>
<xsl:for-each select="Client">
<Person>
<xsl:variable name="var:v1" select="userCSharp:ReturnCounter()" />
<LineNumber>
<xsl:value-of select="$var:v1" />
</LineNumber>
<xsl:variable name="var:v2" select="userCSharp:IncrementCounter()" />
<xsl:value-of select="$var:v2" />
</Person>
</xsl:for-each>
</ns0:PeopleTarget>
Of course, we can change the existing code in the Scripting Functoids so we can get around to this behavior and thus obtain the desired result. However, this example serves to warn that in some scenarios, especially in the use of custom scripts in recursive records or elements, it is necessary to verify and validate the sequence in which the rules (links) are executed.
Conclusion
With this article, we explore some of the common mapping scenarios, trying to dismantle the options that the BizTalk Map engine has taken to fulfill the original intent of the visual map.
When you begin to explore the world of maps, there are two questions that you should evaluate carefully
- What is the best way to solve a problem: guaranteed there are several approaches to solving a common problem. Often deciding which is the best way turns out to be the most difficult. Compiling and analyzing the code generated can be a good start to begin to understand the impact of certain options.
- Incremental Testing: very often, we are tempted to try to solve a mapping problem from start to finish, and only then do we test the solution. Leaving it to the end can make it extremely difficult to detect problems in complex mappings. The scope of testing should be a continuous and incremental process during the creation of maps; tests must be carried out as soon as a significant block is completed.
I hope this kind of hacking can help you to understand the behavior and debugging techniques for these types of elementary problems.
Related links
- How BizTalk Maps Work – Processing model (Part 1)
- How BizTalk Maps Work – Deconstructing a map (Part 2)
Source Code
You can download the source code from:
For those looking to move beyond the basics of message transformation, I highly recommend checking out my eBook, BizTalk Mapping Patterns & Best Practices, published in partnership with BizTalk360.
This resource is a deep dive into the real-world challenges of data transformation. It covers:
- Mapping Patterns: From simple field-to-field links to complex structural shifts.
- Performance Optimization: How to build maps that don’t slow down your environment.
- XSLT vs. Functoids: Knowing exactly when to use built-in tools and when to write custom code.
Whether you are maintaining a legacy BizTalk 2010 environment or planning a migration, these patterns are the foundation of clean, maintainable integration.
Download the full eBook here: BizTalk Mapping Patterns & Best Practices
Hope you find this helpful! If you liked the content or found it useful and would like to support me in writing more, consider buying (or helping to buy) a Star Wars Lego set for my son.

There are 3 maps in series deployed in BizTalk console
A–>B
B–>C
C–>D
If you drop a pickup file for A , what will be the result ?
It all depends.
– If you are using a receive or send port will the 3 maps (only one of them has the maps), then the outcome is B;
– if you are using a receive port will the 3 maps and a send port also with the 3 maps – of course with a filter subscribing, then the outcome is C;
– if you have an orchestration executing the maps then the outcome probably will be D;